
时间: 2024-09-30 16:43:08 作者: 新闻中心
在智能驾驶系统中,CPU算力扮演着至关重要的角色。由于软件系统的复杂性,它需要消耗大量的CPU运算资源。软件系统包含众多中间件,如SOME/IP、自适应AUTOSAR、DDS、ROS等,以及基础软件如定制的Linux BSP、OS抽象层、虚拟机等。此外,与底层硬件关联的内存管理、各种驱动、通讯协议等也大量消耗CPU资源。
在应用层中,路径规划、高精度地图、行为决策等也是CPU资源的主要消耗部分。同时,CPU还负责管理AI运算时的任务调度和存储搬运指令等任务。尽管AI在图像特征提取、分类、BEV变换、矢量地图映射或空间分布等方面具备极其重大作用,但CPU仍然是核心,而AI只是其附属功能。
在衡量算力方面,权重排名依次为AI算力、存储带宽、CPU算力、GPU算力和制造工艺。存储带宽和AI算力具有同等重要性。尽管GPU在某些情况下可以处理FP32数据,发挥及其重要的作用,但大部分车载AI处理部分仅对应INT8位数据。
为了更准确地衡量算力,MAC阵列数量是一个关键指标。例如,谷歌的TPU V1具有65000个FP16 MAC,运行频率为0.7GHz,其算力为91TOPS。而特斯拉第一代FSD的两个NPU,每个具有9216个INT8 MAC,运行频率为2GHz,其总算力为73.7TOPS。至于制造工艺,更先进的工艺意味着更低的功耗。
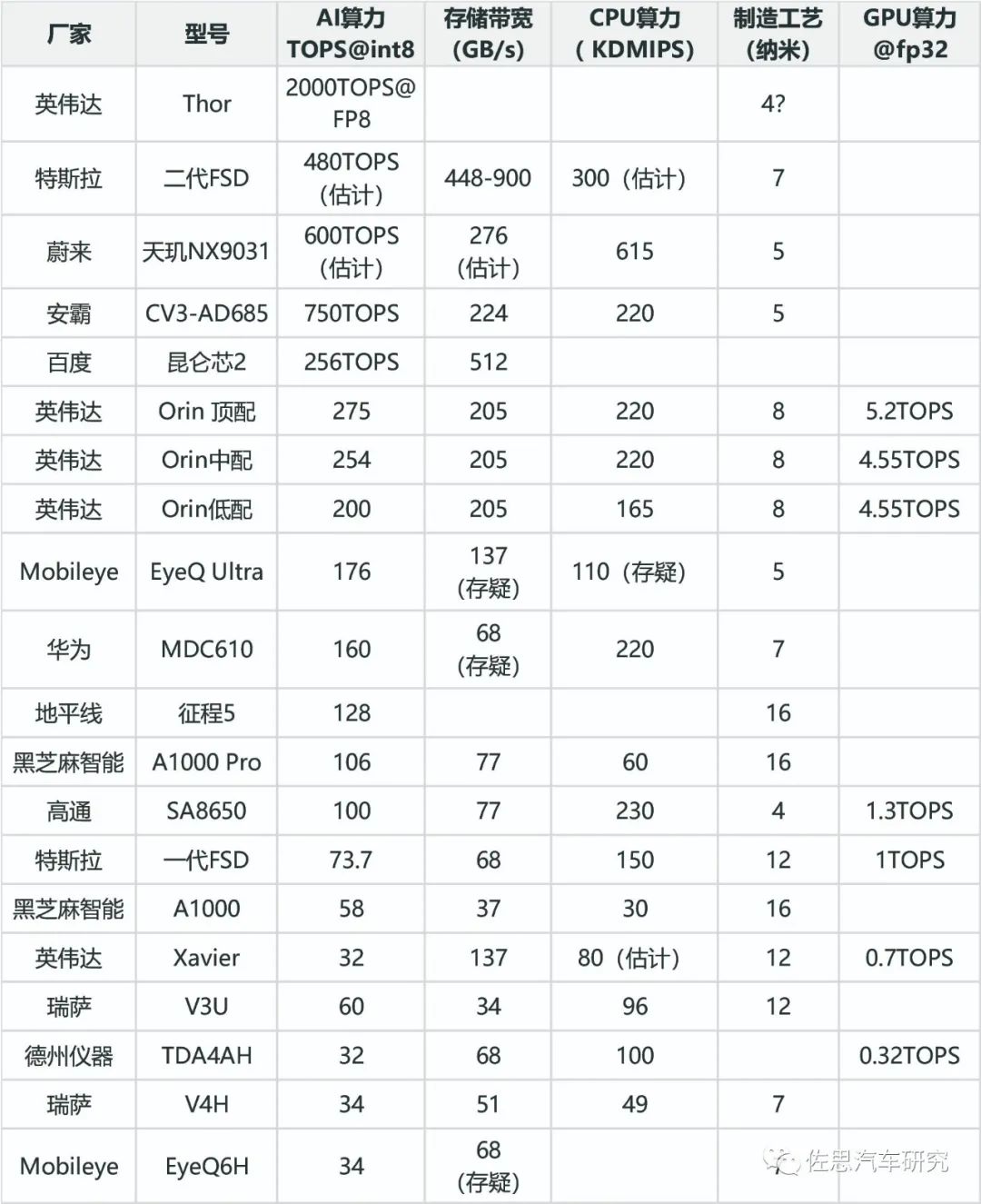
如何计算存储带宽,芯片本身都有存储管理器,这通常是CPU的一部分,决定存储带宽的有两点,首先是CPU支持的存储类型,即存储的物理层和控制器,其次是CPU的存储带宽,LPDDR的存储带宽最高一般是256比特,GDDR可以到384比特,HBM可以到4096甚至8192比特,这些都关联成本,厂家在设计芯片时,会在成本和性能之间找一个平衡点,有些厂家偏重成本,那就64比特甚至32比特,有些偏重性能,如真正的AI芯片,无一例外都是HBM的,成本都在1500美元以上。

上表为常见汽车内存性能与价格对比,显然,一分价钱一分货。英伟达H100是HBM3的最大采购者,每GB的采购价格大约14美元。还有一点需要指出,目前没有车规级GDDR6存储芯片。

存储带宽在智能驾驶系统中扮演着至关重要的角色,其计算方式是将CPU的存储位宽与存储器的Data transfer rate(DDR)相乘,再除以8换算为大写的GB。以英伟达Orin和特斯拉一代FSD为例,Orin的存储位宽为256比特,支持LPDDR5,传输速率为6400MT/s,其存储带宽为204.8GB/s;而特斯拉一代FSD的存储位宽为128比特,支持LPDDR4,传输速率为3200MT/s,其存储带宽为51.2GB/s。
Roof-line模型是解决计算量和访存量问题的理论工具。计算量指的是模型进行一次完整前向传播所发生的浮点运算个数,即模型的时间复杂度。而访存量指的是模型完成一次前向传播过程中所发生的内存交换总量,即模型的空间复杂度。计算量除以访存量能够获得模型的计算强度I,表示此模型在计算过程中每Byte内存交换到底用于进行多少次浮点运算。
由于智能驾驶系统软件异常复杂,会消耗大量的CPU运算资源,软件系统包含众多中间件诸如SOME/IP、自适应AUTOSAR、DDS、ROS等,基础软件包括订制的Linux BSP、OS抽象层、虚拟机等。除此之外,应用层中的路径规划、高精度地图、行为决策等也大量消耗CPU资源。同时CPU也管理AI运算时的任务调度、存储搬运指令等,整体的任务调度、决策自然也是CPU的任务。
在智能驾驶系统中,CPU算力占据核心地位。为了确认和保证系统的流畅运行和高效性能,必须考虑AI算力、存储带宽、CPU和GPU算力以及制造工艺等多种因素。
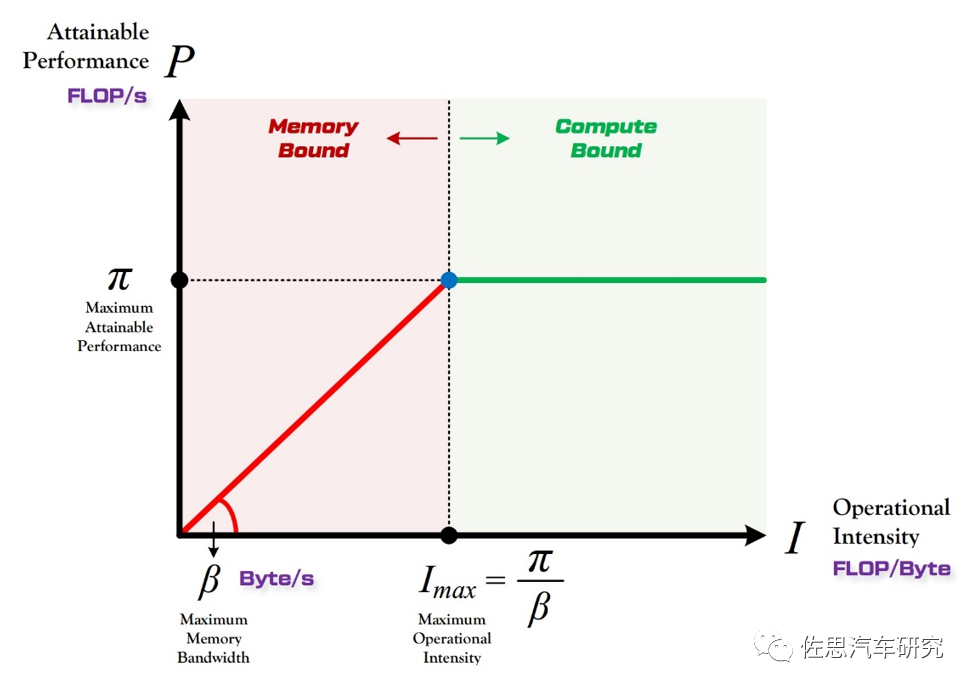
算力决定“屋顶”的高度(绿色线段),带宽决定“房檐”的斜率(红色线段)
在智能驾驶系统中,模型计算的理论性能受到硬件最大理论性能的限制。如果一个模型所需的算力超过了计算平台的理论性能,那么计算平台的利用率将达到100%,此时风险在于处理图像的帧率或FPS可能没办法达到目标帧率。对于智能驾驶来说,主流帧率是30FPS,而高速行驶则需要更高的帧率。
如果模型的算力需求过高,计算平台即使满负荷运转也无法适应,导致帧率下降。在这种情况下,高速行驶会带来风险。一般来说,厂家不会推荐使用算力需求远超理论性能上限的模型。
当计算平台的利用率低于100%时,模型处于Memory-Bound状态。在这个状态下,模型的理论性能P完全由计算平台的带宽上限(房檐的斜率)和模型自身的计算强度I(Intensity)决定。因此,在带宽瓶颈的前提下,计算平台的带宽越陡峭,或者模型的计算强度越大,模型的理论性能P可以呈线性增长。
斜率较低意味着即使计算强度快速增加,计算平台算力的增加也很缓慢,导致计算平台的利用率很低。例如,如果计算平台的理论算力是100TOPS,斜率很低,那么即使很高的计算强度模型的利用率也可能不到50%。这在某种程度上预示着存储带宽决定了计算平台的性能利用率。因此,存储带宽的重要性丝毫不亚于算力,甚至有可能高于算力。这也是特斯拉二代FSD排名第二的根本原因,因为GDDR6的带宽相对于LPDDR具有压倒性优势。

特斯拉第二代FSD芯片采用了三星的7纳米工艺,这一选择主要是出于价格和地理因素的考虑。首先,三星的代工价格远低于台积电,大约只有台积电价格的一半左右。其次,台积电的亚利桑那工厂效率相比来说较低,从2020年开工建设到预计2025年投产,进度缓慢。而三星的德克萨斯奥斯汀二代工厂仅用两年就完工投产,且距离特斯拉总部较近。
第一代FSD使用的是三星的14纳米工艺。根据WikiChip的数据,三星7纳米LPP HD高密度cell方案的晶体管密度高达95.08 MTr/mm²,而HP高性能方案的晶体管密度为77.01 MTr/mm²。相比之下,三星14纳米UHP方案的晶体管密度为26.22 MTr/mm²,HP方案晶体管密度为32.94 MTr/mm²。基本上,三星7纳米的晶体管密度是14纳米的3倍以上。这在某种程度上预示着特斯拉的第二代FSD芯片可以容纳更多的MAC阵列,以此来实现AI性能的三倍提升。考虑到第一代FSD的AI性能为73.7TOPS@INT8,三倍的提升即为221.1TOPS。如果再结合稀疏模型加速技术,算力数字还可以再增长一倍。另外,根据推测,由于二代FSD芯片面积明显大于一代,并且NPU增加到3个,因此其算力可能在500TOPS上下。
特斯拉在二代FSD中还大幅度加强了CPU的性能,采用了三星的Exynos 20核心配置。这进一步证明了CPU在智能驾驶中的重要性。
安霸的CV3可能不为大多数人所熟知,但它在存储带宽方面表现出色,支持最高的LPDDR5X规格,并且具有最高的256比特位宽。这款芯片采用三星的5纳米工艺制造,目前已得到了德国大陆汽车公司的支持。
综上所述,无论是特斯拉还是安霸,都在积极探索更先进的制程工艺和存储技术,以提高AI性能和系统整体表现。随只能驾驶技术的持续不断的发展,这些创新将为未来的汽车带来更高效、更安全的驾驶体验。
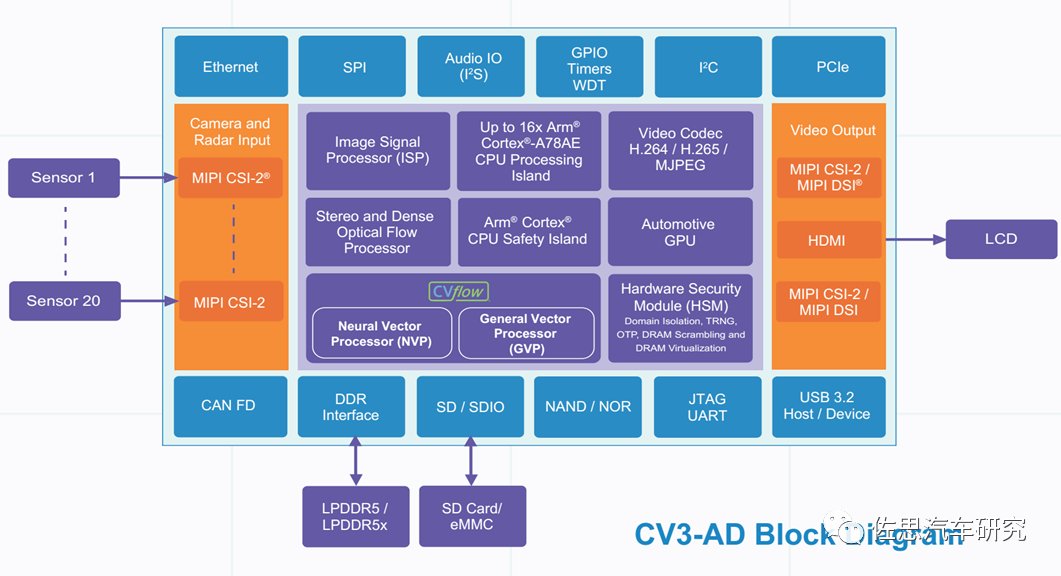
安霸CV3-AD是一款高性能的汽车AI芯片,最高包括了16核心的Coretex-A78AE,具有极高的CPU算力。同时,它也通过了ASIL-B级认证,这在某种程度上预示着它具有高度的可靠性和安全性。在AI算力方面,安霸CV3-AD等效于500TOPS,表现出色。
英伟达、特斯拉和Mobileye等也是汽车AI芯片领域的有名的公司。英伟达的芯片位宽为256比特,而特斯拉和Mobileye的芯片大多是128比特。至于征程6的存储信息,目前尚未公布。
另外,值得一提的是百度旗下的昆仑芯科技。虽然较少人知晓,但昆仑芯科技其实是百度智能芯片及架构部独立后的产物,全称为昆仑芯(北京)科技有限公司。该公司在2021年4月完成了独立融资,估值约为130亿元。在2022年11月29日的百度Apollo Day技术开放日上,第二代昆仑芯宣布已完成在百度无人驾驶车辆RoboTaxi的驾驶系统上的完整适配,并在高阶无人驾驶系统中运行正常。
昆仑芯科技的历史可以追溯到2011年,当时它开始从事AI计算相关工作,早期使用FPGA芯片对AI进行计算加速。在接下来的几年里,昆仑芯科技在百度数据中心部署了超过5000片FPGA芯片,并在2017年累计部署超过12000片。到了2018年,昆仑芯科技决定自研AI芯片,并真正开始启动昆仑芯系列新产品的研发和设计。
第一代昆仑芯于2020年开始大规模部署,采用14纳米工艺和先进的HBM内存、2.5D封装技术。这款芯片刚量产就在百度数据中心里部署了超过2万片。一年后,第二代昆仑芯量产,采用了更先进的7纳米工艺和XPU第二代的架构。同时,它也是业界第一颗采用GDDR6高速显存技术的AI芯片。目前,昆仑芯科技正在研发更先进的第三代AI芯片,针对高阶无人驾驶系统,未来可能会推出定制的车规高性能SoC(系统级芯片)。
综上所述,汽车AI芯片领域的市场之间的竞争激烈,各大厂商都在积极研发高性能、高可靠性和高安全性的产品。而随技术的慢慢的提升和应用场景的不断拓展,这一个市场还有很大的发展空间和潜力。

英伟达对存储系统一向比较重视,全线非常近似,CPU和GPU基本完全相同,AI算力做了特别加强,存储位宽是比较少见的96比特,SA8650是取代上一代SA8540P的,主要是增加了针对功能安全的部分,增加了4个Cortex-R52内核。Mobileye对成本异常重视,也从不公布其存储带宽和支持存储类型,只能猜测。Xavier虽是早期产品,但存储位宽是最高的256比特,所以排名很靠前。
*博客内容为网友个人发布,仅代表博主个人自己的观点,如有侵权请联系工作人员删除。
